Actian Ingres Disaster Recovery
Most production Actian Ingres installations need some degree of disaster recovery (DR). Options range from shipping nightly database checkpoints to off-site storage locations to near real-time replication to a dedicated off-site DR site.
Actian Ingres enterprise hybrid database that ships with built-in checkpoint and journal shipping features which provide the basic building blocks for constructing low-cost, efficient DR implementations. One such implementation is IngresSync, which utilizes Actian Ingres’ native checkpoint/journal shipping and incremental roll-forward capabilities to implement a cost-effective DR solution.
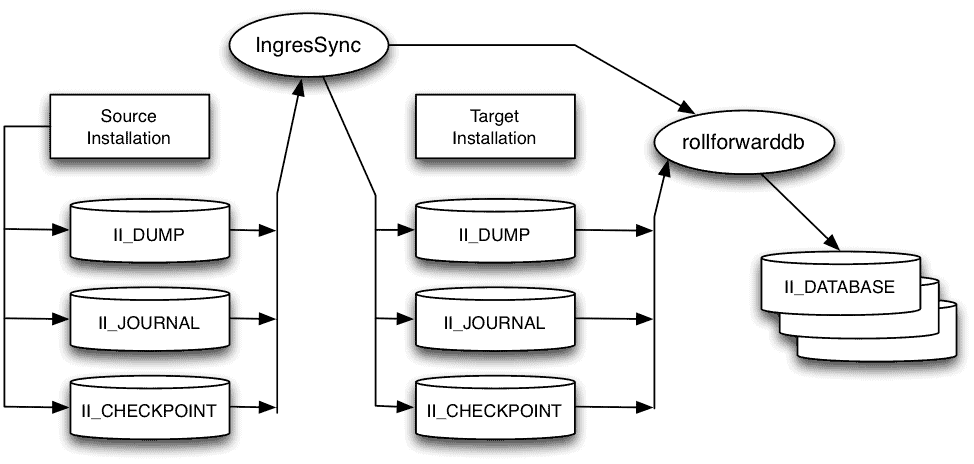
IngresSync works on the concept of source and target Actian Ingres installations. The source installation is the currently active production environment. The target, or multiple targets if needed, kept current by an IngresSync job scheduled to execute on a user-defined interval. Each sync operation copies only journals created since the previous sync and applies those transactions to the targets. Checkpoints taken on the source node are automatically copied to and rolled forward on all targets.
Example
Suppose we have an environment where the production installation is hosted on node corp and we need to create two DR sites dreast and drwest.
The DR nodes each need:
- An Ingres installation at the same version and patch level as corp
- Passwordless SSH configured to and from the other nodes
- Ingres/Net VNODE entries to the other nodes
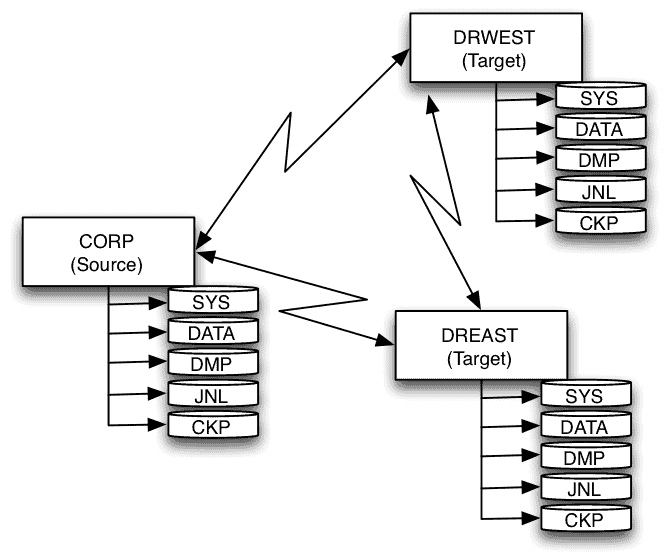
To configure this environment, we must first designate the source and target hosts and apply the latest source checkpoint to the targets.
ingresSync --source=corp --target=dreast,drwest --database=corpdb --iid=II --ckpsync --restart
The two target installations are now synched with the source, and the target databases are in incremental rollforward (INCR_RFP) state. This state allows journals to be applied incrementally to keep the targets in sync with the source. Incremental rollforward is performed by:
ingresSync --hosts=corp,dreast,drwest --database=corpdb --iid=II --jnlsync
When executed, this will close the current journal on the source, copy new journals to the targets, and roll forward those journals to the targets. The journal sync step should be configured to execute at regular intervals using the system scheduler, such as cron. Frequent execution results in minimal sync delay between the source and targets.
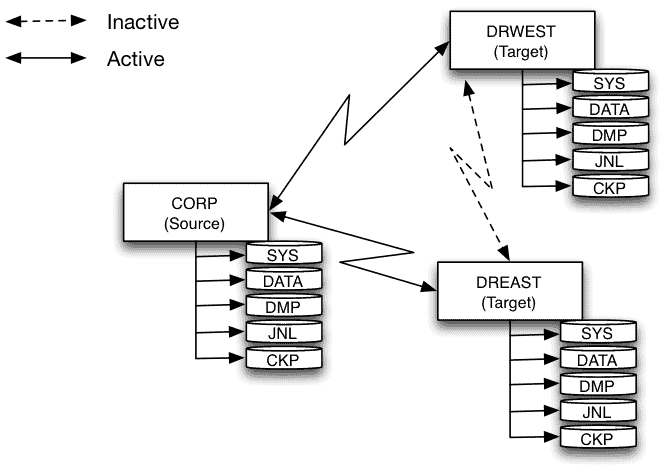
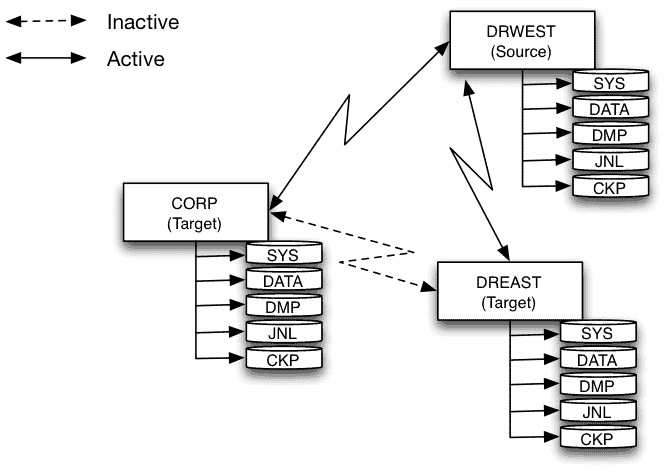
The target installations at dreast and drwest are now in sync with the source installation at corp. Should the corp environment experience a hardware or software failure, we can designate one of the target nodes as the new source and direct client connections to that node. In this case, we’ll designate drwest as the new source and dreast will remain as a target (DR site).
ingresSync --target=drwest --database=corpdb --iid=II --incremental_done
This takes the drwest corpdb database out of incremental rollforward mode; the database will now execute both read and update transactions and is the new source. The dreast database is still in incremental rollforward mode and will continue to functioning as a DR target node.
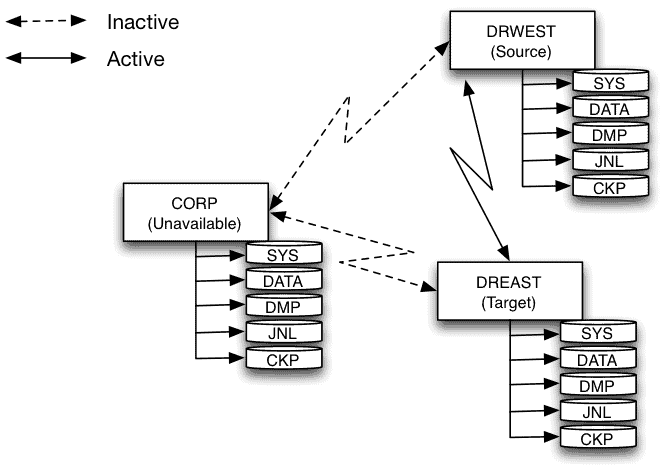
Since the corp node is no longer available, the journal sync job must be started on either drwest or dreast. The journal sync job can be configured and scheduled to execute on all three nodes using the –strict flag. In this case, the job determines if it executes on the current source node; if so it will execute normally. If executing on a target, the job will simply terminate. This configuration allows synchronization to continue even as node roles change.
Once corp is back online it can be brought back into the configuration as a DR target.
ingresSync --source=drwest --target=corp --database=corpdb --iid=II --ckpsync --restart
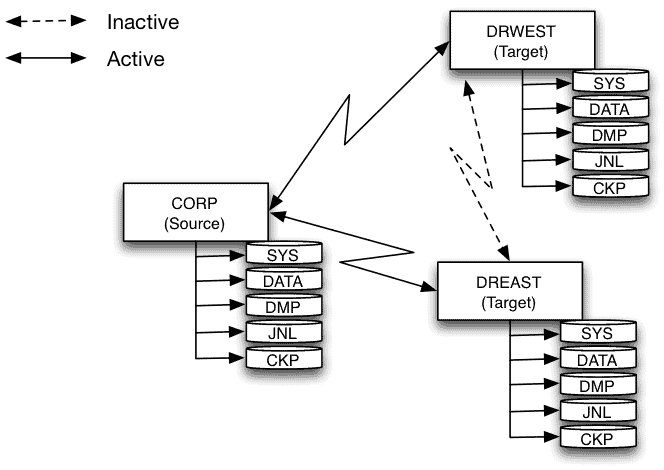
At some point, we may need to revert to the original configuration with corp as the source. The steps are:
- Terminate all database connections to drwest
-
Sync
corp
with
drwest
to ensure
corp
is current ingresSync --source=drwest --target=corp --database=corpdb --iid=II --jnlsync
-
Reassign node roles ingresSync --target=corp --database=corpdb --iid=II --incremental_done ingresSync --source=corp --target=drwest --database=corpdb --iid=II --ckpsync --restart
Summary
IngresSync is one mechanism for implementing a DR solution. It is generally appropriate in cases where some degree of delay is acceptable and the target installations have little or no database user activity. Target databases can be used for read only/reporting applications with the stipulation that incremental rollforwards cannot run while there are active database connections. The rollforward process will catch up on the first refresh cycle when there are no active database connections.
The main pros and cons of the alternative methods of delivering disaster recovery for Actian Ingres are outlined below:
| Feature | Checkpoint Shipping | IngresSync | Replication |
| Scope | Database | Database | Table |
| Granularity | Database | Journal | Transaction |
| Sync Frequency | Checkpoint | User Defined | Transaction |
| Target Database | Read/Write(1) | Read Only | Read/Write(2) |
- Target database supports read and write operations but all changes are lost on the next checkpoint refresh.
- Target database supports read and write operations but there may be update conflicts that require manual resolution.
Note: IngresSync currently runs on Linux and Microsoft Windows. Windows environments require the base Cygwin package and rsync.
The post Actian Ingres Disaster Recovery appeared first on Actian.
Read More
Author: Emma McGrattan